Голосовое управление IH
-
А в сторону микрофонов "Шорох" почему не смотрите? Когда занимался СОТВ, вполне нормальное качество обеспечивали. Да и вообще в "охранной" технике большой выбор микрофонов
Вообще всегда проблема сигнал/шум. Если в доме тихо, то можете на первом этаже сказать и "ассистент" с микрофоном шорох на втором услышит и распознает. А вот если будет играть музыка/телевизор (в городе - открыто окно и прочее), то ничего не распознается. Кроме этого в помещении может возникать эффект эхо… А массив микрофон поддерживает DOA и AEC, поэтому легко справляется с задачей фильтрации полезного сигнала! Посмотрите видео (послушайте входные/выходные треки, которые получаются после ЦОС) на тот же ReSpeaker Mic Array 2.0 - эффект отличный! По сути является USB-звуковой картой и с него можно взять стерео выход подав аудио на усилитель мощности. Я описывал уже на нескольких сайтах концепцию голосового ассистента, который находится в каждой комнате/помещении (компьютер, микрофон под потолком по центру комнаты, интерфейс/питание - POE, усилитель НЧ на борту - подключается хорошая потолочная акустика) и может воспроизводить уведомления от умного дома, а с помощью того же LMS является частичкой мультирума.
Я тестировал Orange Pi Zero (по аналогу подключена PAM8610, питание 12В на OPiZ преобразователь 12В->5В 3А) в качестве единицы LMS, даже прикупил 2 пары потолочной акустики - результат выше моих ожиданий. Хоть и говорят, что LMS - что LMS устарело, но концепция очень интересная, а для меня достаточная. Поэтому все же склоняюсь реализовать шилд для OPiZ + PAM8610 + POE и какой-нибудь Mic Array.
ПО LMS - можно почитать тут.
Шорох отличные микрофоны, только их нужно через какой-то микшер собирать, чтобы в единую точку подключения завести со всех комнат, а так хороший бюджетный вариант. В majordomo голосовое управление реализовано вроде бы, думаю в IH тоже допилят как руки дойдут)
См. выше. По мне он идеален для записи звука со всеми шумами, чтобы это мог прослушать человек и понять что там происходит. Для распознавания голоса необходима серьезная ЦОС, с которой может справится только отдельный звуковой процессор или ПЛИС. Обратите внимание, что IT-гиганты используют именно Mic Array с ЦОС на борту. Даже в тех же бюджетных поделках яндекса скорее всего есть чип цифровой обработки сигнала.
И да - mdmTerminal2 - это как раз мажордомная тема.
-
Коллеги, добрый день!
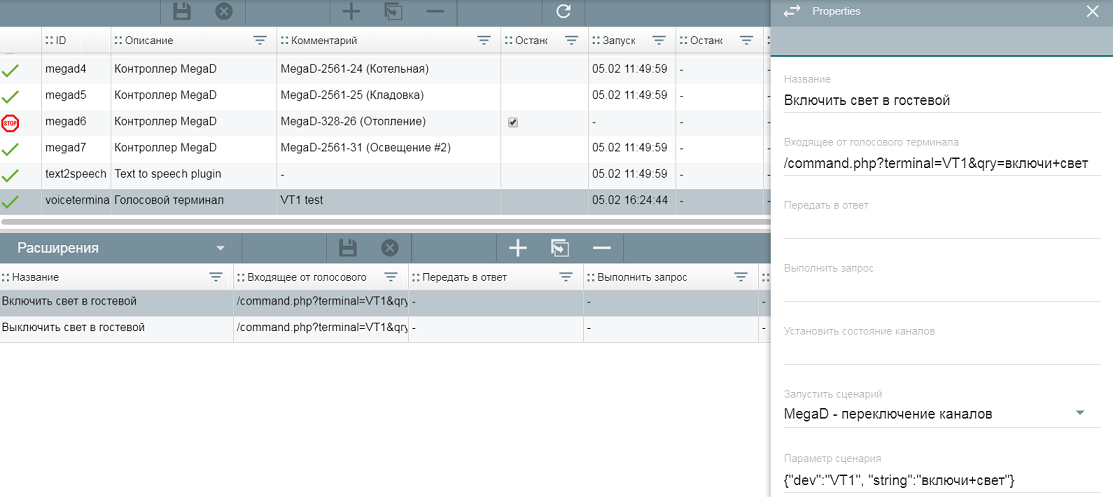
Я вчера топорно (поскольку совсем не программист) "перепилил" плагин MegaD, назвав его VoiceTerminal. Сделал так чтобы в нем не было каналов, но он мог слушать какой-нибудь порт. На этот порт ранее озвученный mdmTerminal2, а в моем исполнении - это shsTerminal2, присылает GET-request, который в самом простом виде выглядит так:
/command.php?terminal=VT1&qry=%D0%B2%D0%BA%D0%BB%D1%8E%D1%87%D0%B8+%D1%81%D0%B2%D0%B5%D1%82http-сервер плагина делает decodeURIComponent(request.url) и в итоге имеем:
/command.php?terminal=VT1&qry=включи+светВ плагине заносим "Расширения" - название, request (который должен прийти) и сценарий (который будет управлять устройствами) с параметрами:
Плагин штатным образом сравнивает полученный и декодированный url со своими extrapattern и если в таблице есть подходящий запускает сценарий, передавая в него нужные параметры. В самом простом случае сценарий выглядит так:/** * @name VoiceTerminal - управление устройствами * @desc При возникновении событий от VoiceTerminal выполнить действия * @version 4 */ const Lamp_Guest = Device("LAMP1_01"); script({ start(param) { const obj = JSON.parse(param); if(obj.dev == "VT1") { if(obj.string == "включи+свет") { if(Lamp_Guest.isOff()) { Lamp_Guest.on(); this.log(obj.dev+ " - " +Lamp_Guest.name+ " включен"); } else { this.log(obj.dev+ " - " +Lamp_Guest.name+ " уже включен!"); exit; } } if(obj.string == "выключи+свет") { if(Lamp_Guest.isOn()) { Lamp_Guest.off(); this.log(obj.dev+ " - " +Lamp_Guest.name+ " выключен"); } else { this.log(obj.dev+ " - " +Lamp_Guest.name+ " был выключен!"); exit; } } } } });В итоге моя версия shsTerminal2 распознает ключевое слово на основе голосовых моделей и команду, которую по http передает серверу iH. Плагин voiceterminal получает команду и запускает сценарий для переключения устройств.
Планирую все что есть выложить на гитхаб. А также попытаюсь допилить плагин в части:
1. Чтобы параметры для сценария формировались по умолчанию.
2. Чтобы плагин в ответ терминалу мог выдать сообщение типа: tts:"Свет в гостевой включен". Для этого нужно сделать передачу данных по соккету и закодировать текст UTF-8 в url.
3. Удалить не нужный код из плагина.
Кроме этого, для удобной настройки shsTerminal2 нужно сделать ему веб-интерфейс.
Надеюсь на помощь программистов iH в выполнении п.2-3. Поскольку пока не понял почему в httpclient в function httpGet есть какие-то обращения к серверу по соккетам, но при этом нет нигде connect, write, да и не объявлена библиотека net. Ну а в самом исходнике плагина MegaD, наверное больше благодаря мне :oops: , наворочено "будь здоров"!
-
Слушается микрофон сервера или микрофон устройства, на котором запущен клиент?
-
Слушается микрофон сервера или микрофон устройства, на котором запущен клиент?
При желании mdmTerminal2 можно легко поставить и на сервер УД. Но смысл есть, наверное, только если это квартира - подключить к серверу USB микрофон (массив микрофонов) и вынести его в "главное помещение" откуда скорее всего удастся распознать команду из всех других помещений. Однако mdmTerminal2 изначально позиционировался как отдельная железка, которая выступает в роли "IP-колонки" для использования в мультируме с наличием голосового ассистента.
-
Коллеги, добрый день!
Я вчера топорно (поскольку совсем не программист) "перепилил" плагин MegaD, назвав его VoiceTerminal….
В итоге моя версия shsTerminal2 распознает ключевое слово на основе голосовых моделей и команду, которую по http передает серверу iH. Плагин voiceterminal получает команду и запускает сценарий для переключения устройств.
Добрый день!
Классно :!:
Планирую все что есть выложить на гитхаб.
Очень хорошо. Для этого нужно:
1. Зарегистрироваться на github. Эта учетная запись для сервиса в целом
2. Прислать нам ваш логин и предполагаемое название плагина. Ваше название - voiceterminal?
Мы создаем на github.com/intrahouseio пустой репозитарий для вашего плагина,
Вам придет на почту приглашение: intrahouseio has invited you to collaborate on the intrahouseio/plugin-voiceterminal repository
Приняв приглашение, вы получите инструкции от github-а, как начать работать.
Предварительно желательно установить git локально. И хотя сейчас можно редактировать файлы в репозитарии на github-е напрямую через browser, обычно разработка идет в таком порядке:
1. Проект локально разрабатывается, тестируется. Изменения фиксируются локально (git commit).
2. На каком-то этапе делается git push в удаленный репозитарий (на github)
3. При совместной разработке, если кто-то поменял код, вы делаете git pull, и имеете у себя свежую версию для дальнейшей разработки.
В интернете полно информации по работе с git-ом, например
https://git-scm.com/book/ru/v2/Основы-Git-Создание-Git-репозитория
2. Чтобы плагин в ответ терминалу мог выдать сообщение типа: tts:"Свет в гостевой включен". Для этого нужно сделать передачу данных по соккету и закодировать текст UTF-8 в url…
Поскольку пока не понял почему в httpclient в function httpGet есть какие-то обращения к серверу по соккетам, но при этом нет нигде connect, write, да и не объявлена библиотека net.
Вам модуль httpclient не нужен. Ответные сообщения можно делать напрямую, закодировать через encodeURIComponent()
Вы ведь будете отправлять по http? Тогда библиотека net не нужна, connect тоже не нужен. Все уже сделано до нас
")
Нужен модуль http , который инкапсулирует работу с сокетами по протоколу http
const http = require("http");
Далее достаточно сделать http.get:
http.get('http://192.168.0.xx….......');
Если вам нужно только отправить, результат не важен - это все
3. Удалить не нужный код из плагина.
Вам не нужен модуль httpclient.js
Также в plugin.js можно удалить функцию setConfig и все, начиная с timers:[]
Манифест нужно почистить, но это можно сделать позднее
Ну а в самом исходнике плагина MegaD, наверное больше благодаря мне :oops: , наворочено "будь здоров"!
Иногда бывает полезно посмотреть на вещи с другой стороны
-
Вам модуль httpclient не нужен. Ответные сообщения можно делать напрямую, закодировать через encodeURIComponent()
Вы ведь будете отправлять по http? Тогда библиотека net не нужна, connect тоже не нужен. Все уже сделано до нас
Нужен модуль http , который инкапсулирует работу с сокетами по протоколу http
const http = require("http");
Далее достаточно сделать http.get:
http.get('http://192.168.0.xx….......');
Если вам нужно только отправить, результат не важен - это все
Все же мне скорее нужен net, поскольку там "This service requires use of the WebSocket protocol or raw TCP/IP".
Если при получении сообщения от VT отправлять принудительную команду типа http://192.168.9.192/tts:123 или ws://192.168.9.192/tts:123, то сервер терминала возвращает:
07.02 10:59:47.882 voiceterminal1: localhost <= 192.168.9.192 response: statusCode=426А ведь это делается с помощью функции sendFullUr, но опять же через httpGet, которая есть в httpclient:
function sendFullUrl(fullUrl) { try { let furl = ut.doSubstitute(fullUrl, { pwd: plugin.params.pwd }); httpclient.httpGet( { url: url.parse(furl).path, host: url.parse(furl).hostname || plugin.params.host, port: url.parse(furl).port || plugin.params.port, stopOnError: false }, logger ); } catch (e) { logger.log("Error sending request " + fullUrl + " : " + e.message); } }Но опять же мне нужно в любое время плагину дать команду типа:
this.pluginCommand({ unit:"voiceterminal1", command:"tts:" +Lamp_Guest.name+ " включен"});Поскольку терминал может озвучивать любую информацию! А если подключить плагин Google VA в терминале, то можно общаться и с голосовым помощником Google, имея синхронизацию с серверами со всеми вытекающими.
Вам не нужен модуль httpclient.js
Также в plugin.js можно удалить функцию setConfig и все, начиная с timers:[]
Манифест нужно почистить, но это можно сделать позднее
Да, то же самое я уже сделал. Интересует что это такое - почему тут вбиты какие-то параметры по умолчанию? Что такое doCmd - нигде не нашел:
module.exports = { params: { host: "192.168.0.14", port: 7999, lport: 8999 }, doCmd: "", setParams(obj) { if (typeof obj == "object") { Object.keys(obj).forEach(param => { if (this.params[param] != undefined) this.params[param] = obj[param]; }); this.doCmd = ut.doSubstitute(this.params.cmdreq); } },И вообще, структура плагинов разная - сравнить MegaD и ping, например. Зачем у MegaD runplugin.js и adapter.js?
-
Все же мне скорее нужен net, поскольку там "This service requires use of the WebSocket protocol or raw TCP/IP".
Если нужен TCP сокет, то конечно, это совсем другое дело.
В MegaD весь обмен делается через http, поэтому там нет net
Для создания соединения по TCP нужно действительно использовать net, это стандартная библиотека nodejs, вот документация
https://nodejs.org/api/net.html
Если кратко, то:
const net = require("net"); // Подключиться, создать клиента const client = net.createConnection( { host, port }, () => { logger.log(" Connected"); }); client.on("error", e => { client.end(); logger.log("Connection error:" + e.code); // process.exit(1); }); // TCP сокет позволяет отправлять и получать сообщения после установки соединения // Для отправки: client.write(msg); // Входящие сообщения: client.on("data", data => { // data - Входящее сообщение });Но опять же мне нужно в любое время плагину дать команду типа:
> this.pluginCommand({ unit:"voiceterminal1", command:"tts:" +Lamp_Guest.name+ " включен"}); >Поскольку терминал может озвучивать любую информацию! А если подключить плагин Google VA в терминале, то можно общаться и с голосовым помощником Google, имея синхронизацию с серверами со всеми вытекающими.
Круто. Вам в плагине нужно сделать обработку command как в MegaD и просто отправлять в сокет: client.write(msg)
Интересует что это такое - почему тут вбиты какие-то параметры по умолчанию? Что такое doCmd - нигде не нашел:
Параметры по умолчанию - это параметры по умолчанию
На случай запуска без сервера или другого форс-мажораdoCmd - это команда по умолчанию, вида "/%pwd%/?cmd="
Используется при формировании команды в функции formCmd, если другая команда не определена
И вообще, структура плагинов разная - сравнить MegaD и ping, например.
Структура разная - и это нормально.
ping использует EventEmitter и написана с использованием синтаксиса классов. Можно писать в любом стиле
Если Вы про net - ping работает по протоколу icmp и использует дополнительный пакет net-ping . В принципе плагин -обертка над этой библиотекой. net там глубоко внутри, можете посмотреть в папке node_modules
Зачем у MegaD runplugin.js и adapter.js?
runplugin.js для запуска плагина без сервера. Для работы этот модуль не нужен, только для отладки
adapter.js - Для работы MegaD этот модуль нужен, вам - не нужен. Используется для подмены стандартных операций чтения данных
P.S. Если хотите использовать WebSocket, то стандартной библиотекой не обойтись, нужно ставить дополнительную. Их несколько разных
-
Добрый день,
Коллеги, подскажите пожалуйста как Вы видите работу с микрофоном
1. Активация по команде или интерактивное выполнение команды ?
2. Окончание команды по тишине заданного времени ?
3. Отсечка шума, команда не распознается пока не превысит установленный уровень ?
4. Как планируете подключать микрофон, на уровне железа ?
-
@dev:
Добрый день,
Коллеги, подскажите пожалуйста как Вы видите работу с микрофоном
1. Активация по команде или интерактивное выполнение команды ?
2. Окончание команды по тишине заданного времени ?
3. Отсечка шума, команда не распознается пока не превысит установленный уровень ?
4. Как планируете подключать микрофон, на уровне железа ?
Я случайно натолкнулся на проект mdmTerminal. В нем реально уже все что можно реализовано - https://github.com/Aculeasis/mdmTerminal2/wiki. Настройки расписаны тут - https://github.com/Aculeasis/mdmTerminal2/wiki/settings.ini. По вопросам:
1. Активация по ключевому слову (работает snowboy, но есть и другие варианты) на основе записанных фраз и скомпилированных голосовых моделей. Причем голосовые модели можно сделать для разных людей и в секции [persons] каждой модели прописать имя человека, тогда на сервер УД будет передаваться имя человека.
Причем в режиме chrome_mode = on между ключевым словом и командой не нужна даже пауза - все распознается на лету и триггер (ключевое слово) и команда.
2. Я так понял, что пока это определяется настройкой:
<quote>> # Лимит времени на запись после того как терминал распознал речь, в секундах.phrase_time_limit = 12
3. Там очень много настроек для этого (например, секция [noise_suppression] и [listener]). Snowboy справляется с задачей очень хорошо. Именно благодаря ему никакие левые команды не проходят.
4. Тут есть как минимум 2 варианта:
-
Поднимать voiceterminal на том же сервере что и сервер УД. Соответственно в него подключить USB-микрофон, который вынести в нужное место. Вариант скорее для небольшой квартиры.
-
Поднимать voiceterminal на отдельной железке (например, те же Orange Pi Zero/One/PC или см. проект Ass shield в Telegram), которая по Ethernet/Wi-Fi будет доступна в любом помещении дома. Кроме этого, есть резон сделать из нее единицу мультирума (см.LMS/squeezebox/squeezelite). Однако если будет много таких железок, то нужно подумать как ими всеми управлять (отсылать сообщения если активен датчик движения или что-то подобное).
По микрофонам я уже писал ранее. Однако парадокс софта mdmTerminal2 в том, что я его тестирую на Orange Pi PC со встроенным микрофоном,у которого на максимум задрано усиление (микрофон под штатным корпусом), и все это лежит на шумящем системнике!!! При этом уровень распознавания очень хороший!
-
-
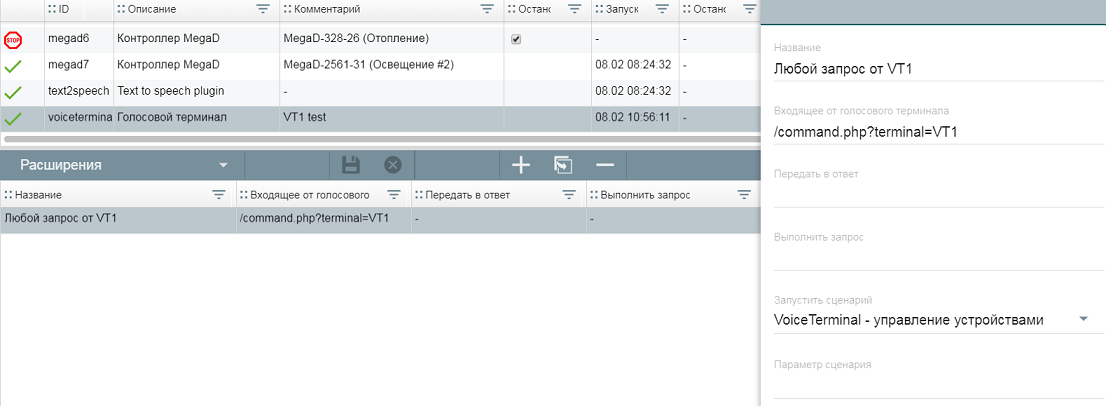
Почти победил плагин voiceterminal в части отправки команд в сам терминал по соккетам - команды с сервера УД воспроизводятся.
Сейчас "расширения" плагина выглядит так, и в принципе этого достаточно при наличии одного голосового терминала!
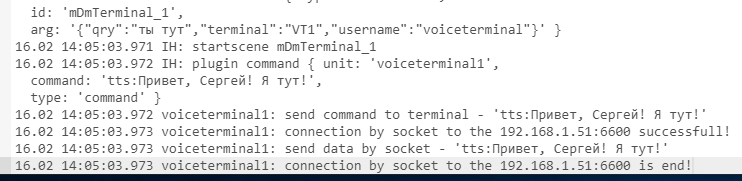
Лог плагина при приеме сообщения от голосового терминала и передаче ему команды:08.02 14:53:38.367 voiceterminal1: 192.168.10.1 => localhost:8999 HTTP GET /command.php?qry=какая+погода&username=aleksey&terminal=VT1 08.02 14:53:38.368 voiceterminal1: 192.168.10.1 <= localhost:8999 08.02 14:53:38.369 voiceterminal1: { type: 'startscene', id: 'VoiceTerminal_ControlOfDevices', arg: '{"qry":"какая погода","username":"aleksey","terminal":"VT1"}' } 08.02 14:53:38.369 IH: startscene VoiceTerminal_ControlOfDevices 08.02 14:53:38.406 IH: plugin command { unit: 'voiceterminal1', command: 'tts:сейчас на улице -23 градуса и влажность 65 процентов', type: 'command' } 08.02 14:53:38.408 voiceterminal1: send command to terminal - 'tts:сейчас на улице -23 градуса и влажность 65 процентов' 08.02 14:53:38.557 voiceterminal1: Socket connection to the 192.168.9.192:7999 successfull! 08.02 14:53:38.558 voiceterminal1: localhost => 192.168.9.192:7999 send data - 'tts:сейчас на улице -23 градуса и влажность 65 процентов' 08.02 14:53:43.673 voiceterminal1: localhost <= 192.168.9.192:7999 data -Ну и сценарий, который у меня работает с моим VT1:
/** * @name VoiceTerminal - управление устройствами * @desc При возникновении событий от голосового терминала выполнить действия * @version 4 */ const dt_s = Device("STEMP4_01"); const dh_s = Device("SHUMIDITY4_01"); const lamp_guest = Device("LAMP1_01"); script({ device: "", //Переменная для устройства terminal: "", //Переменная для имени терминала start(param) { const obj = JSON.parse(param); this.terminal = obj.terminal; this.log("### Receive message from - " +this.terminal+ '. Username - ' +obj.username+ ". Qry - " +obj.qry); //Голосовой терминал VT1 if(this.terminal == "VT1") { if(obj.qry == "ты тут") { if(obj.username == "aleksey") this.pluginCommand({ unit:"voiceterminal1", command:"tts:Привет, Алексей! Конечно я тут!"}); else this.pluginCommand({ unit:"voiceterminal1", command:"tts:Привет, я вас не узнала. Вы кто?"}); } else if(obj.qry == "какая погода") { let temp = Math.round(dt_s.value); let hum = Math.round(dh_s.value); let temp_unit = this.FormLineEnd(temp, "градус"); let hum_unit = this.FormLineEnd(hum, "процент"); this.pluginCommand({ unit:"voiceterminal1", command:"tts:сейчас на улице " +temp+ " " +temp_unit+ " и влажность " +hum+ " " +hum_unit }); } else if(obj.qry == "включи свет гостевой" || obj.qry == "включи свет в гостевой") { this.device = lamp_guest; if(this.device.isOff()) { this.device.on(); this.addListener(this.device, 'TTStoVTdevOn') } else this.TTStoVTdevisOn(); } else if(obj.qry == "выключи свет гостевой" || obj.qry == "выключи свет в гостевой") { this.device = lamp_guest; if(this.device.isOn()) { this.device.off(); this.addListener(this.device, 'TTStoVTdevOff') } else this.TTStoVTdevisOff(); } else this.pluginCommand({ unit:"voiceterminal1", command:"tts:Я не знаю такую команду!"}); } }, //Функция формирования окончаний единиц измерений - если unit = "градус", то будет "градуса" и "градусов" FormLineEnd(val, unit) { let part = 0; let string = ""; let val_abs = Math.abs(val); if(val_abs > 20) part = val_abs % 10; else part = val_abs; if(part == 1) string = unit; else if(part > 1 && part < 5) string = unit+ "а"; else string = unit+ "ов"; return string; }, TTStoVTdevOn() { this.pluginCommand({ unit:"voiceterminal1", command:"tts:" +this.device.name+ " включен"}); //this.log("To " +this.terminal+ " - 'tts:" +this.device.name+ " включен'"); this.exit(); }, TTStoVTdevOff() { this.pluginCommand({ unit:"voiceterminal1", command:"tts:" +this.device.name+ " выключен"}); //this.log("To " +this.terminal+ " - 'tts:" +this.device.name+ " выключен'"); this.exit(); }, TTStoVTdevisOn() { this.pluginCommand({ unit:"voiceterminal1", command:"tts:" +this.device.name+ " уже был включен!"}); //this.log("To " +this.terminal+ " - 'tts:" +this.device.name+ " уже был включен!'"); this.exit(); }, TTStoVTdevisOff() { this.pluginCommand({ unit:"voiceterminal1", command:"tts:" +this.device.name+ " уже был выключен!"}); //this.log("To " +this.terminal+ " - 'tts:" +this.device.name+ " уже был выключен!'"); this.exit(); } });
-
Для тех кто решит на какой-нибудь железке (в том числе сам сервер умного дома) развернуть mdmTerminal2:
1. Устанавливаем пакеты с github:
git clone https://github.com/Aculeasis/mdmTerminal2
cd mdmTerminal2
./scripts/install.sh
2. Проверям работает ли запись и воспроизведение звука:
arecord -d 5 __.wav && aplay __.wav && rm __.wav
3. Копируем asound_pi.conf (для аналогового микрофона OPiZ) в /etc:
cp -p asound/asound_pi.conf /etc/asound.conf
4. Пробный запуск терминала (создается первоначальный конфиг):
env/bin/python -u src/main.py
5. Если все ОК, то можно поправить settings.ini (см.ниже):
nano src/settings.ini
6. Если есть папка plugins (ls -X src/plugins), то установим веб-конфигуратор:
env/bin/python -m pip install bottle
cd src/plugins
git clone https://github.com/Aculeasis/mdmt2-web-config
7. Добавить сервис в systemd - терминал будет запускаться автоматически:
cd ../../
./scripts/systemd_install.sh
8. Записываем фразы и компилируем голосовые модели:
env/bin/python -u scripts/tester.py
record 1 1 - прослушать play 1 1
record 1 2 - прослушать play 1 2
record 1 3 - прослушать play 1 3
compile 1
save - сохраняется конфигурация и сервис терминала перезагружается
9. Теперь в settings.ini в секции [models] будет присутствовать модель с активационной фразой:
model1.pmdl = Алиса
10.В settings.ini в секции [persons] можно задать соответствие модели с человеком:
model1.pmdl = aleksey
model5.pmdl = dima
По изменению настроек в settings.ini. Либо через ssh, либо с помощью веб-конфигуратора:
[settings]
providertts = yandex //Голос Алисы благозвучнее
phrase_time_limit = 10 //Уменьшить чтобы был более быстрый отклик
providerstt = yandex //google распознает лучше если есть шумы/эхо
chrome_mode = off //По умолчанию включен - распознавание кодового слова и команды происходит одновременно
Если отключить, то сначала распознает кодовое слово и потом записывает команду, отправляя ее providerstt
По мне - с отключенным режимом кодовое слово распознается лучше, а распознавание providerstt
не постоянное, как в случае с chrome_mode = on (меньше трафика и никто не слушает постоянно).
no_hello = on //Обязательно включить если chrome_mode = off
no_background_play = on //Чтобы терминал не слушал себя когда сервер iH отправляет ему "tts:текстдля озвучивания"
[majordomo]
ip = 192.168.11.99:11051 //ip сервера ih и слушающий порт плагина
terminal = VT1 //Название терминала, которое будет приходить на сервер iH
username = voiceterminal //Username, который будет приходить на сервер iH по умолчанию
password =
heartbeat_timeout = 0
object_method =
object_name =
linkedroom =
[listener]
vad_mode = energy
vad_chrome = snowboy
stream_recognition = on
energy_dynamic = on
silent_multiplier = 1.0
energy_lvl = 0
vad_lvl = 0
Из основных проблем терминала - на 4-м ядре запаздывает активация (выход из stand-by) усилителя звуковой карты, в итоге короткие звуки типа ding.wav/dong.wav не воспроизводятся. Поэтому в режиме chrome_mode = off не понятно сколько по длительности нужна пауза между активационной фразой и командой.
-
Выложил на гитхабе плагин - https://github.com/intrahouseio/intraHouse.plugin-voiceterminal
-
Для тех кто решит на какой-нибудь железке (в том числе сам сервер умного дома) развернуть mdmTerminal2:
1. Устанавливаем пакеты с github:
git clone https://github.com/Aculeasis/mdmTerminal2
cd mdmTerminal2
./scripts/install.sh
2. Проверям работает ли запись и воспроизведение звука:
arecord -d 5 __.wav && aplay __.wav && rm __.wav
3. Копируем asound_pi.conf (для аналогового микрофона OPiZ) в /etc:
cp -p asound/asound_pi.conf /etc/asound.conf
4. Пробный запуск терминала (создается первоначальный конфиг):
env/bin/python -u src/main.py
5. Если все ОК, то можно поправить settings.ini (см.ниже):
nano src/settings.ini
6. Если есть папка plugins (ls -X src/plugins), то установим веб-конфигуратор:
env/bin/python -m pip install bottle
cd src/plugins
git clone https://github.com/Aculeasis/mdmt2-web-config
7. Добавить сервис в systemd - терминал будет запускаться автоматически:
cd ../../
./scripts/systemd_install.sh
8. Записываем фразы и компилируем голосовые модели:
env/bin/python -u scripts/tester.py
record 1 1 - прослушать play 1 1
record 1 2 - прослушать play 1 2
record 1 3 - прослушать play 1 3
compile 1
save - сохраняется конфигурация и сервис терминала перезагружается
9. Теперь в settings.ini в секции [models] будет присутствовать модель с активационной фразой:
model1.pmdl = Алиса
10.В settings.ini в секции [persons] можно задать соответствие модели с человеком:
model1.pmdl = aleksey
model5.pmdl = dima
По изменению настроек в settings.ini. Либо через ssh, либо с помощью веб-конфигуратора:
[settings]
providertts = yandex //Голос Алисы благозвучнее
phrase_time_limit = 10 //Уменьшить чтобы был более быстрый отклик
providerstt = yandex //google распознает лучше если есть шумы/эхо
chrome_mode = off //По умолчанию включен - распознавание кодового слова и команды происходит одновременно
Если отключить, то сначала распознает кодовое слово и потом записывает команду, отправляя ее providerstt
По мне - с отключенным режимом кодовое слово распознается лучше, а распознавание providerstt
не постоянное, как в случае с chrome_mode = on (меньше трафика и никто не слушает постоянно).
no_hello = on //Обязательно включить если chrome_mode = off
no_background_play = on //Чтобы терминал не слушал себя когда сервер iH отправляет ему "tts:текстдля озвучивания"
[majordomo]
ip = 192.168.11.99:11051 //ip сервера ih и слушающий порт плагина
terminal = VT1 //Название терминала, которое будет приходить на сервер iH
username = voiceterminal //Username, который будет приходить на сервер iH по умолчанию
password =
heartbeat_timeout = 0
object_method =
object_name =
linkedroom =
[listener]
vad_mode = energy
vad_chrome = snowboy
stream_recognition = on
energy_dynamic = on
silent_multiplier = 1.0
energy_lvl = 0
vad_lvl = 0
Из основных проблем терминала - на 4-м ядре запаздывает активация (выход из stand-by) усилителя звуковой карты, в итоге короткие звуки типа ding.wav/dong.wav не воспроизводятся. Поэтому в режиме chrome_mode = off не понятно сколько по длительности нужна пауза между активационной фразой и командой.
Добрый день. Вроде все настроил. Только в процессе выполнения сценария Алиса не возвращает голосовое сообщение в терминал. В отладчике фраза от Алисы идет, а голосом не воспроизводится. mdm Terminal2 сам не собирал, скачал готовый образ из https://majordomo.smartliving.ru/forum/viewtopic.php?f=5&t=5460&hilit=mdm+terminal2 (4 ядро рекомендуется). Подскажите пожалуйста что не так?
-
Добрый день. Вроде все настроил. Только в процессе выполнения сценария Алиса не возвращает голосовое сообщение в терминал. В отладчике фраза от Алисы идет, а голосом не воспроизводится. mdm Terminal2 сам не собирал, скачал готовый образ из https://majordomo.smartliving.ru/forum/viewtopic.php?f=5&t=5460&hilit=mdm+terminal2 (4 ядро рекомендуется). Подскажите пожалуйста что не так?
Сергей, ничего не могу сказать пока не покажите что в этот момент есть в логе терминала. Вообще желательно поставить терминал самому (у меня на OPiZ собирался не долго) и особенно веб-конфигуратор (см.п.6) - в нем посмотрите REMOTE_LOG и скорее что-то станет понятнее. По логу плагина iH - сервер открывает соединение и получает команду.
-
Добрый день. Вроде все настроил. Только в процессе выполнения сценария Алиса не возвращает голосовое сообщение в терминал. В отладчике фраза от Алисы идет, а голосом не воспроизводится. mdm Terminal2 сам не собирал, скачал готовый образ из https://majordomo.smartliving.ru/forum/viewtopic.php?f=5&t=5460&hilit=mdm+terminal2 (4 ядро рекомендуется). Подскажите пожалуйста что не так?
Сергей, ничего не могу сказать пока не покажите что в этот момент есть в логе терминала. Вообще желательно поставить терминал самому (у меня на OPiZ собирался не долго) и особенно веб-конфигуратор (см.п.6) - в нем посмотрите REMOTE_LOG и скорее что-то станет понятнее. По логу плагина iH - сервер открывает соединение и получает команду.
Собрать самому… наверное лучше... но я пошел по пути наименьшего сопротивления
") Покопаюсь еще и решу тогда. Лог выкладываю.
Покопаюсь еще и решу тогда. Лог выкладываю.
-
Добрый день. Вроде все настроил. Только в процессе выполнения сценария Алиса не возвращает голосовое сообщение в терминал. В отладчике фраза от Алисы идет, а голосом не воспроизводится. mdm Terminal2 сам не собирал, скачал готовый образ из https://majordomo.smartliving.ru/forum/viewtopic.php?f=5&t=5460&hilit=mdm+terminal2 (4 ядро рекомендуется). Подскажите пожалуйста что не так?
Сергей, ничего не могу сказать пока не покажите что в этот момент есть в логе терминала. Вообще желательно поставить терминал самому (у меня на OPiZ собирался не долго) и особенно веб-конфигуратор (см.п.6) - в нем посмотрите REMOTE_LOG и скорее что-то станет понятнее. По логу плагина iH - сервер открывает соединение и получает команду.
Собрать самому… наверное лучше... но я пошел по пути наименьшего сопротивления
Покопаюсь еще и решу тогда. Лог выкладываю.А "ларчик просто открывался", установил номер порта 7999 (увидел этот номер при записи фраз) и перезагрузил IH :lol:
-
Сергей, ничего не могу сказать пока не покажите что в этот момент есть в логе терминала. Вообще желательно поставить терминал самому (у меня на OPiZ собирался не долго) и особенно веб-конфигуратор (см.п.6) - в нем посмотрите REMOTE_LOG и скорее что-то станет понятнее. По логу плагина iH - сервер открывает соединение и получает команду.
Собрать самому… наверное лучше... но я пошел по пути наименьшего сопротивления
Покопаюсь еще и решу тогда. Лог выкладываю.А "ларчик просто открывался", установил номер порта 7999 (увидел этот номер при записи фраз) и перезагрузил IH :lol:
Здорово, что получилось! Я так и не добрался до вашего лога на выходных…
iH не обязательно перезагружать - нужно остановить/запустить плагин, поскольку я еще не разобрался как автоматом перезапускать плагин при изменении сетевых настроек. А вообще порт связи с терминалом "по умолчанию" - 7999. Вы его почему-то поменяли на 6600 и я не обратил на это внимание.
-
Собрать самому… наверное лучше... но я пошел по пути наименьшего сопротивления
Покопаюсь еще и решу тогда. Лог выкладываю.А "ларчик просто открывался", установил номер порта 7999 (увидел этот номер при записи фраз) и перезагрузил IH :lol:
Здорово, что получилось! Я так и не добрался до вашего лога на выходных…
iH не обязательно перезагружать - нужно остановить/запустить плагин, поскольку я еще не разобрался как автоматом перезапускать плагин при изменении сетевых настроек. А вообще порт связи с терминалом "по умолчанию" - 7999. Вы его почему-то поменяли на 6600 и я не обратил на это внимание.
Порт поменял в процессе экспериментов со звуком. А вообще прикольная система. Основная сложность это подбор параметров чувствительности микрофона. Но у меня практического применения эта система вероятно не найдёт, двое маленьких детей своим шумным поведением «свели Алису с ума»! :lol:
-
Порт поменял в процессе экспериментов со звуком. А вообще прикольная система. Основная сложность это подбор параметров чувствительности микрофона. Но у меня практического применения эта система вероятно не найдёт, двое маленьких детей своим шумным поведением «свели Алису с ума»! :lol:
Да, в условиях шума все не айс… банально - включен телевизор и терминал уже ничего не понимает. Да что там телевизор - жена читает книжку сыну, а терминал уже не дозовешься. Создатель терминала говорит, что нужно более длинное кодовое слово, у него голосовые модели для "Булочка с корицей" и "Гугл с корицей".
Вариант подавления шума - это массив микрофонов а-ля "ReSpeaker Mic Array v2.0". И еще подумать как на него через сеть завести звук телевизора/смартфона и прочее аудио чтобы "выходной" сигнал вычитался из сигнала канала микрофонов. Тогда будет работать как та же Яндекс.Станция - если громкость не выше среднего уровня, то все команды понимает.
А вообще, на этапе сегодняшнего развития техники, я понял, что голосовые ассистенты это удел одиноких людей...
-
Голосовое управление нужно, чтобы не загромождать интерфейс кнопками запуска сценариев. Но для срабатывания нужно подойти к ближайшему интерфейсу.
И в ситуациях, когда заняты руки. Например на кухне, в момент готовки/резки/мойки, или в мастерской, или в санузлле.
Таких зон не очень много, и туда нужно выносить интерфейс системы с говорилкой и микрофоном. Чтобы на кухне можно было не хватаясь за полотенце голосовой командой ворота открыть.
И в этих зонах можно каждому интерфейсу сделать свои уникальные настройки шумоподавления под конкретную ситуацию.