Голосовое управление IH
-
Выложил на гитхабе плагин - https://github.com/intrahouseio/intraHouse.plugin-voiceterminal
-
@sergeyygr:
Добрый день. Вроде все настроил. Только в процессе выполнения сценария Алиса не возвращает голосовое сообщение в терминал. В отладчике фраза от Алисы идет, а голосом не воспроизводится. mdm Terminal2 сам не собирал, скачал готовый образ из https://majordomo.smartliving.ru/forum/viewtopic.php?f=5&t=5460&hilit=mdm+terminal2 (4 ядро рекомендуется). Подскажите пожалуйста что не так?
Сергей, ничего не могу сказать пока не покажите что в этот момент есть в логе терминала. Вообще желательно поставить терминал самому (у меня на OPiZ собирался не долго) и особенно веб-конфигуратор (см.п.6) - в нем посмотрите REMOTE_LOG и скорее что-то станет понятнее. По логу плагина iH - сервер открывает соединение и получает команду.
-
@sergeyygr:
@sergeyygr:
Сергей, ничего не могу сказать пока не покажите что в этот момент есть в логе терминала. Вообще желательно поставить терминал самому (у меня на OPiZ собирался не долго) и особенно веб-конфигуратор (см.п.6) - в нем посмотрите REMOTE_LOG и скорее что-то станет понятнее. По логу плагина iH - сервер открывает соединение и получает команду.
Собрать самому… наверное лучше... но я пошел по пути наименьшего сопротивления
") Покопаюсь еще и решу тогда. Лог выкладываю.
Покопаюсь еще и решу тогда. Лог выкладываю.А "ларчик просто открывался", установил номер порта 7999 (увидел этот номер при записи фраз) и перезагрузил IH :lol:
Здорово, что получилось! Я так и не добрался до вашего лога на выходных…
iH не обязательно перезагружать - нужно остановить/запустить плагин, поскольку я еще не разобрался как автоматом перезапускать плагин при изменении сетевых настроек. А вообще порт связи с терминалом "по умолчанию" - 7999. Вы его почему-то поменяли на 6600 и я не обратил на это внимание.
-
@sergeyygr:
Порт поменял в процессе экспериментов со звуком. А вообще прикольная система. Основная сложность это подбор параметров чувствительности микрофона. Но у меня практического применения эта система вероятно не найдёт, двое маленьких детей своим шумным поведением «свели Алису с ума»! :lol:
Да, в условиях шума все не айс… банально - включен телевизор и терминал уже ничего не понимает. Да что там телевизор - жена читает книжку сыну, а терминал уже не дозовешься. Создатель терминала говорит, что нужно более длинное кодовое слово, у него голосовые модели для "Булочка с корицей" и "Гугл с корицей".
Вариант подавления шума - это массив микрофонов а-ля "ReSpeaker Mic Array v2.0". И еще подумать как на него через сеть завести звук телевизора/смартфона и прочее аудио чтобы "выходной" сигнал вычитался из сигнала канала микрофонов. Тогда будет работать как та же Яндекс.Станция - если громкость не выше среднего уровня, то все команды понимает.
А вообще, на этапе сегодняшнего развития техники, я понял, что голосовые ассистенты это удел одиноких людей...
-
Голосовое управление нужно, чтобы не загромождать интерфейс кнопками запуска сценариев. Но для срабатывания нужно подойти к ближайшему интерфейсу.
И в ситуациях, когда заняты руки. Например на кухне, в момент готовки/резки/мойки, или в мастерской, или в санузлле.
Таких зон не очень много, и туда нужно выносить интерфейс системы с говорилкой и микрофоном. Чтобы на кухне можно было не хватаясь за полотенце голосовой командой ворота открыть.
И в этих зонах можно каждому интерфейсу сделать свои уникальные настройки шумоподавления под конкретную ситуацию.
-
@sergeyygr:
Ну да… Шкворчат котлеты, микроволновка гудит, играет радио (что-бы не скучно было готовкой заниматься), подходишь к терминалу... А в ответ - "я не знаю такую команду!!!" или "вы ничего не сказали", берешь полотенце, вытираешь руки и... нажимаешь кнопку открытия ворот

Ну вот для этого и нужна продвинутая звуковая карта, которая отрежет лишние шумы и выпилит из распознаваемого звука звуки от радио/телевизора/музыки и т.д. Поэтому за такими вещами как предлагает ReSpeaker - будущее голосового распознавания.
-
@sergeyygr:
Ну да… Шкворчат котлеты, микроволновка гудит, играет радио (что-бы не скучно было готовкой заниматься), подходишь к терминалу... А в ответ - "я не знаю такую команду!!!" или "вы ничего не сказали", берешь полотенце, вытираешь руки и... нажимаешь кнопку открытия ворот
из дешевых решений - гейт + направленный микрофон.
По уровню громкости отсекается шум.
Говорить нужно заведомо громче фонового шума, заняв позицию в зоне направленности.
Делали так озвучку зала в 90-х, когда конгресс систем на рынке в России не было доступных.
У президиума на столах микрофоны-лягушки с направленностью в сторону сидящего за столом, в противоположную сторону от зала.
и как бы зал не гудел, начало громкой и четкой речи включало микрофон и выводило его на колонки в зал.
Могли говорить 2, 3, все в президиуме одновременно. Включались все микрофоны, потоки микшировались, и подавались в колонки.
Я же написал про уникальные для каждого места настройки шумоподавления.
Следующий по дешевизне способ - параметрический эквалайзер. Просто давится полоса, в которой максимальный уровень шума.
Третий - это фоновая музыка ( или сигнал с второго микрофона, находящегося в стороне от говорящего) переворачивается зеркально по фазе и примешивается в микрофонный канал говорящего. Значительная часть сторонних звуков сама себя компенсирует.
А есть "интелектуальные". Распознают, например, шум бегущей воды, и его удаляют. Сохраняя все тембральные нюансы оставшегося сигнала…
Но вам же не песни в студии записывать, а сигнал электронному болвану послать...
P.S. Все давно придумано. Есть такое бесплатное ПО для музыкантов.
https://www.native-instruments.com/en/products/komplete/guitar/guitar-rig-5-player/amps-and-effects/
Даже им можно отфильтровать большую часть лишнего из аудио потока.
А уж платные версии... Или цифровые студии...
Ну хотя бы микшерский пульт
https://www.bandlab.com/products/cakewalk
- многоканальный цифровой интерфейс....
(4-х канальный для примера)
-
Для тех кто использует mdmTerminal2 вместе с iH выкладываю сценарий, который выводит в веб-интерфейс (точнее на закладку "Параметры" бокового меню плагина) текущие параметры mdmTerminal2. Мультисценарии не поддерживают класс устройств "Plugin", поэтому их приходится прописывать вручную в сценарии.
Вообще моей семье оказалось довольно удобно общаться с такой "настраиваемой" на сервере Алисой - спросить какую-нибудь информацию (сколько времени, какая погода, кто такой…, что такое..., какая температура...), дать ей команду (включи свет в..., выключи свет в..., включи вентиляцию, давай спать), поприветствовать ее, спросит как дела, сказать спасибо или просто узнать "ты человек"?

Скрипт сценария. Сам сценарий приложен в виде zip-файла к текущему сообщению.
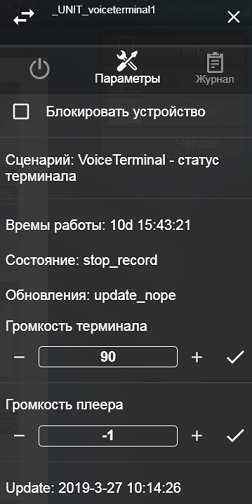
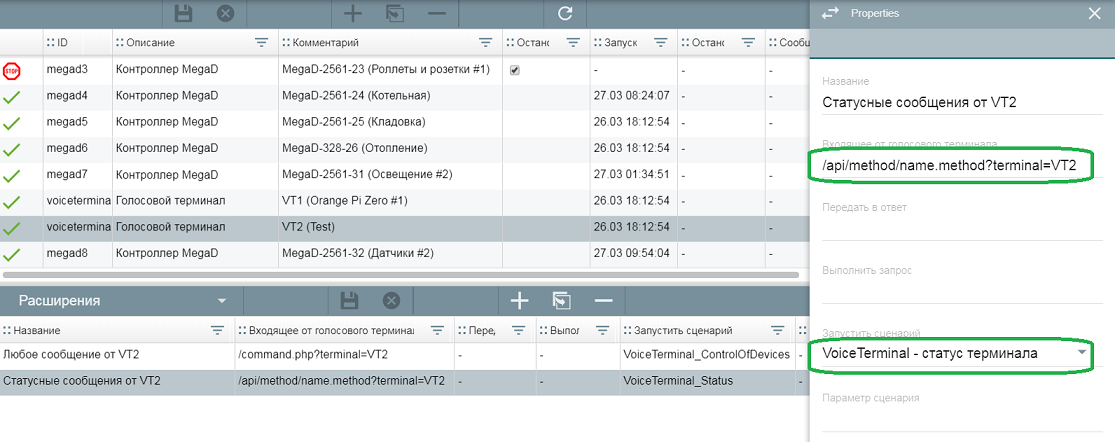
/** * @name VoiceTerminal - статус терминала * @desc Обработка состояния терминала * @version 4 */ const dev1 = Device("_UNIT_voiceterminal1", [ {"name":"uptime", "note":"Времы работы", "type":"string", "val":""}, {"name":"status", "note":"Состояние", "type":"string", "val":""}, {"name":"updater", "note":"Обновления", "type":"string", "val":""}, {"name":"set_volume", "note":"Громкость терминала", "type":"number", "val":50}, {"name":"set_music_volume", "note":"Громкость плеера", "type":"number", "val":50}, {"name":"last_update", "note":"Update", "type":"string", "val":""} ]); const dev2 = Device("_UNIT_voiceterminal2", [ {"name":"uptime", "note":"Времы работы", "type":"string", "val":""}, {"name":"status", "note":"Состояние", "type":"string", "val":""}, {"name":"updater", "note":"Обновление", "type":"string", "val":""}, {"name":"set_volume", "note":"Громкость терминала", "type":"number", "val":50}, {"name":"set_music_volume", "note":"Громкость плеера", "type":"number", "val":50}, {"name":"last_update", "note":"Last update", "type":"string", "val":""} ]); startOnChange([dev1,dev2]); script({ start(param) { let device = ''; let flag_volume = 0; //Скрипт запускается плагином с параметрами if(param !== undefined) { const obj = JSON.parse(param); //Выбор устройства if(obj.terminal == "VT1") { device = dev1; } else if(obj.terminal == "VT2") { device = dev2; } //Конвертация времени из секунд в часы let days = Math.floor(obj.uptime/86400); let hours = Math.floor((obj.uptime % 86400)/3600); let minutes = Math.floor((obj.uptime % 3600)/60); let seconds = obj.uptime % 60; let time = days+ "d " +((hours < 10) ? "0" : "")+hours+ ":" +((minutes < 10) ? "0" : "")+minutes+ ":" +((seconds < 10) ? "0" : "")+seconds; //Обновление параметров устройства if(obj.uptime !== undefined) device.setParam("uptime", time); if(obj.status !== undefined) device.setParam("status", obj.status); if(obj.updater !== undefined) device.setParam("updater", obj.updater); if(obj.volume !== undefined) device.setParam("set_volume", obj.volume); if(obj.music_volume !== undefined) device.setParam("set_music_volume", obj.music_volume); device.setParam("last_update", this.GetDate()); } //Скрипт запускается по startOnChange else { //Проверка с какого устройства поступила команда if(this.isChanged(dev1, "set_volume")) { device = dev1; flag_volume = 1; } else if(this.isChanged(dev2, "set_volume")) { device = dev2; flag_volume = 1; } else if(this.isChanged(dev1, "set_music_volume")) { device = dev1; flag_volume = 2; } else if(this.isChanged(dev2, "set_music_volume")) { device = dev2; flag_volume = 2; } //Установка громкости на нужном терминале if(flag_volume == 1) this.SetVolumeTerminal(device); else if(flag_volume == 2) this.SetVolumeMusic(device); } }, GetDate() { return new Date().toLocaleString('ru-RU'); }, SetVolumeTerminal(device) { let unit = device.id.replace('_UNIT_', ''); let command = device.getParam('set_volume'); this.pluginCommand({unit: unit, command:"volume_q:" +command}); }, SetVolumeMusic(device) { let unit = device.id.replace('_UNIT_', ''); let command = device.getParam('set_music_volume'); this.pluginCommand({unit: unit, command:"music_volume_q:" +command}); } });Чтобы скрипт работал, необходимо в расширениях плагина VoiceTerminal в поле "Входящее от голосового терминала" прописать:
/api/method/name.method?terminal=VT2Где:
name - это любое имя object_name в разделе [Smarthome] настроек mdmTerminal2,
method - это любое имя object_method в разделе [Smarthome] настроек mdmTerminal2,
VT2 - это любое имя terminal в разделе [Smarthome] настроек mdmTerminal2
Кроме этого, в поле "Запустить сценарий" текущего расширения выбрать скрипт "VoiceTerminal_Status".
Кстати, вот незадача…в этом месте можно выбрать скрипт, в котором не объявлены устройства, а в скрипте они объявлены! Поэтому нужно временно из скрипта удалить строчки:
const dev1 = Device("_UNIT_voiceterminal1", [ {"name":"uptime", "note":"Времы работы", "type":"string", "val":""}, {"name":"status", "note":"Состояние", "type":"string", "val":""}, {"name":"updater", "note":"Обновления", "type":"string", "val":""}, {"name":"set_volume", "note":"Громкость терминала", "type":"number", "val":50}, {"name":"set_music_volume", "note":"Громкость плеера", "type":"number", "val":50}, {"name":"last_update", "note":"Update", "type":"string", "val":""} ]); const dev2 = Device("_UNIT_voiceterminal2", [ {"name":"uptime", "note":"Времы работы", "type":"string", "val":""}, {"name":"status", "note":"Состояние", "type":"string", "val":""}, {"name":"updater", "note":"Обновление", "type":"string", "val":""}, {"name":"set_volume", "note":"Громкость терминала", "type":"number", "val":50}, {"name":"set_music_volume", "note":"Громкость плеера", "type":"number", "val":50}, {"name":"last_update", "note":"Last update", "type":"string", "val":""} ]); startOnChange([dev1,dev2]);Сохранить сценарий, выбрать его в расширениях плагина и сохранить созданное расширение. Снова вернуть строчки в сценарий и сохранить его.
Вот так у меня выглядит вкладка "Параметры" плагина VoiceTerminal. Громкость плеера - это регулировка громкости плеера-клиента LMS (zqueezelite) или плеера mpd, установленного на mdmTerminal2:
Пример настроек в расширении плагина VoiceTerminal:
-
Тут обратил внимание, что у меня не отображаются статусы голосовых терминалов - на вкладке "Параметры" - пусто. Не буду рассказывать в чем была проблема, но в итоге из одного сценария сделал два:
1. Статус терминала - запускается при поступлении сообщения от терминала на сервер:
02.09 12:57:17.337 voiceterminal2: { type: 'startscene', id: 'VoiceTerminal_Status', arg: '{"uptime":"313596","volume":"100","terminal":"VT2","music_volume":"100","username":"voiceterminal"}' } 02.09 12:57:17.342 IH: startscene VoiceTerminal_Status
2. Управление терминалом - запускается по изменению значений слайдеров на вкладке "Параметры"
В сценариях прописано 2 голосовых терминала.Теперь задача другая - если терминалы стоят в смежных помещениях/на разных этажах и оба слышат пользователя, то нужно выбрать на какой терминал сервер должен среагировать. Как вариант для критерия - уровень RMS. То есть если распознавание ключевого слова прошло успешно, то вместе с результатом распознавания передаем уровень RMS (сейчас есть min,max,avr). Таким образом, примерно в одно и то же время на сервер придет два сообщения от двух терминалов -от какого терминала Average RMS по уровню больше, от того и анализируем сервером текст команды.
В сценарии такую обработку мне не удалось пока реализовать, но скорее это дело плагина. Но "поковыряться" с плагином пока времени нет:(
Еще один вариант работы терминала, интегрированного в систему "Умный дом", находящегося в отдельной комнате - "прослушка" во время появления движения. Если срабатывает датчик движения, то на терминал посылаем команду listener:on, иначе после тайм-аута 10-30 минут посылаем listener:off. Однако - надо все пробовать…
-
@Alex_Jet большое спасибо за плагин,
а можно как-то переправить звук с mdmTerminal-а на другое физическое устройство?
Например, у меня потолочная акустика подключена к i386 серверу на котором установлен IH. А терминал я установил на Orange Pi Zero - который находится рядом, под потолком, смысла городить еще один динамик на Orange Pi Zero вроде бы и нет...
-
@div115, раз на сервере стоит iH, то вероятно можно использовать голосовой плагин самого iH? А может все-таки к акустике подключить малинку/апельсинку?
Вообще теоретически на это сервер можно установить mdmTerminal2 и в сценарии tts осуществлять через второй плагин. По крайней мере у меня несколько терминалов и я могу на любой вывести tts. А вот сервер УД у меня - только сервер, находящийся в темном черном углу. Даже LMS живет на другой железке.
-
Пользователь @Alex_Jet написал в Голосовое управление IH:
раз на сервере стоит iH, то вероятно можно использовать голосовой плагин самого iH?
да, наверное так можно, но реакция на кодовое слово вроде бы воспроизводится mdmTerminal-ом локально - на апельсине,
А может все-таки к акустике подключить малинку/апельсинку?
да, - на крайний вариант так и сделаю - раздраконю и прицеплю какие-нибудь usb колонки. Существующая потолочная аккустика - не вариант, т-к к ним идут только акустические провода от усилителя в электрощитовой (усилитель подключен к серверу IH) - а электрощитовая в подвале... + еще потолок уже сделан, - перепротянуть провода не получится, - но в 1,5 метрах от потолочной акустки есть отверстие под универсальный датчик - туда затянута из электрощитовой витая пара, - на нее планировал повесить апельсин с MDMтерминалом, микрофоном и датчиками, - питать планировал по пасив-пое.
Вообще теоретически на это сервер можно установить mdmTerminal2 и в сценарии tts осуществлять через второй плагин. По крайней мере у меня несколько терминалов и я могу на любой вывести tts.
этот вариант, как я понимаю, тоже не решает вопроса с озвучкой ответа на ключевое слово.
А вот сервер УД у меня - только сервер, находящийся в темном черном углу. Даже LMS живет на другой железке.
у меня на физ. сервере живет IH, LMS и SqueezePlayer
конечно хотелось бы перенаправить весь звук от апельсинки на сервер по сети, но пока не знаю как это сделать...
-
Пользователь @div115 написал в Голосовое управление IH:
у меня на физ. сервере живет IH, LMS и SqueezePlayer
конечно хотелось бы перенаправить весь звук от апельсинки на сервер по сети, но пока не знаю как это сделать...Я думаю, что самой правильной концепцией является:
- Отдельный железный сервер УД + LMS +Media, к которому подключен только кабель Eth
- По всей квартире/дому разбросаны железки с подключеным Eth (на крайний случай Wi-Fi) и акустикой. На борту у железок - mdmTerminal2 и squeezelite.
Поэтому ваш вариант перенести OPiZ в потолочное отверстие рядом с акустикой мне нравится намного больше. Сам хочу разработать плату для установки на нее OPiZ + микрофон с усилителем на TS472 + усилитель (хотя бы PAM8610) мощности + светодиодное кольцо на базе WS28xx, но пока руки не доходят...
И да...я до конца не понял, но похоже у Вас связка LMS ->squeezelite не работает? Если так, то это проще простого! На клиентах ставим squeezelite и их находит LMS (в его настройках на закладке "Информация" есть раздел "Информация о плеере"). Собственно на главной странице LMS сверху справа будет выпадающий список из плееров)
Passive-poe в реализации OPiZ очень плохой вариант... Лучше взять переходники для passive-poe и снимать хотя бы 12В, подавая сразу на усилитель (тот же PAM8610 - хорошая вещь!), а для OPiZ поставить step-down! - кушает она не мало и греется прилично!
-
Пользователь @Alex_Jet написал в Голосовое управление IH:
Отдельный железный сервер УД + LMS +Media, к которому подключен только кабель Eth
да, так оно у меня и есть
Сам хочу разработать плату для установки на нее OPiZ + микрофон с усилителем на TS472 + усилитель (хотя бы PAM8610) мощности + светодиодное кольцо на базе WS28xx, но пока руки не доходят...
по моей задумке, - на апельсин хочу повесить
- датчик движения,
- i2c датчики температуры/влажности, освещенности, СО2,
- микрофон,
- динамики с усилителем из колонок типа: http://microlab.com/ru/catalog/stereosistemyi/usb/md-122/ - кмк будет вполне бюджетно
(исключение коридоры 1,2 этажей - там уже стоит потолочная акустика) - возможно лед ленту W2812
И да...я до конца не понял, но похоже у Вас связка LMS ->squeezelite не работает? Если так, то это проще простого! На клиентах ставим squeezelite и их находит LMS (в его настройках на закладке "Информация" есть раздел "Информация о плеере"). Собственно на главной странице LMS сверху справа будет выпадающий список из плееров)
да, - связка есть, - так у меня работает интернет-радио и медиатека, squeezelite у меня еще кроме сервера стоит на планшете с IH-kiosk - но тут источник звука LMS. Как указать какому плееру воспроизводить звук с конкретного MDMтерминала - я не знаю, буду благодарен если подскажете.
Passive-poe в реализации OPiZ очень плохой вариант... Лучше взять переходники для passive-poe и снимать хотя бы 12В, подавая сразу на усилитель (тот же PAM8610 - хорошая вещь!), а для OPiZ поставить step-down! - кушает она не мало и греется прилично!
спасибо за совет, - у меня как раз есть свободные порты в passive-poe-панели, заколхоженной из 24х портовой patch-панели и б/п от ноутбука.
-
Пользователь @div115 написал в Голосовое управление IH:
по моей задумке, - на апельсин хочу повесить
датчик движения,
i2c датчики температуры/влажности, освещенности, СО2,
микрофон,
динамики с усилителем из колонок типа: http://microlab.com/ru/catalog/stereosistemyi/usb/md-122/ - кмк будет вполне бюджетно
(исключение коридоры 1,2 этажей - там уже стоит потолочная акустика)
возможно лед ленту W2812Не рекомендую делать такую солянку. Вообще OPiZ довольно не стабильная железка (у меня есть простая и Plus) и хоть она имеет gpio, но лучше их использовать для реализации полноценного mdmTerminal2 (управление режимами усилителя, управление кольцом из светодиодов WS28xx). Очень сильно греется и по хорошему ей надо тормозить CPU и занижать питание. В unix очень не удобно (ИМХО) работать с I2C и 1W датчиками.
А датчики температуры/влажности/СО2, датчик движения и прочее лучше повесить на специализированные контроллеры! Я повсеместно использую MegaD-2561 (версия в моноблоке в последней ревизии - вообще улет!)Как указать какому плееру воспроизводить звук с конкретного MDMтерминала - я не знаю, буду благодарен если подскажете.
Объясните по другому. Не понимаю вашу задачу! mdmTerminal2 - это железка "сама в себе", которую можно интегрировать в любой умный дом. У меня сейчас используется 3 терминала - в центре гостевой (по сути охватывает половину первого этажа), на втором этаже в спальне/кабинете и у сына в комнате. При этом благодаря LMS во всех вышеперечисленных комнатах сделан мультирум.
-
Пользователь @Alex_Jet написал в Голосовое управление IH:
Объясните по другому. Не понимаю вашу задачу! mdmTerminal2 - это железка "сама в себе", которую можно интегрировать в любой умный дом. У меня сейчас используется 3 терминала - в центре гостевой (по сути охватывает половину первого этажа), на втором этаже в спальне/кабинете и у сына в комнате. При этом благодаря LMS во всех вышеперечисленных комнатах сделан мультирум.
допустим у меня есть несколько контроллеров на OPZ (OPZ_1, OPZ_2, OPZ_3 и т.д.) на которых стоит MDM и squeezelite, так же у меня есть IH c LMS который видит все плееры.
Возможно ли реализовать следующую задачу:
MDM установленный на OPZ_1 получил запрос через микрофон OPZ_1 но голосовой ответ будет выведен на динамики OPZ_2 .
-
Пользователь @div115 написал в Голосовое управление IH:
MDM установленный на OPZ_1 получил запрос через микрофон OPZ_1 но голосовой ответ будет выведен на динамики OPZ_2 .
Я такую задачу не решал, однако с помощью pulse audio такое сделать точно можно! То есть на локальном OPZ_1 в asound.conf надо прописать внешнюю звуковую карту в качестве pcm.playback. А с помощью pulse audio на OPZ_2 сделать сетевую звуковую карту.
Но опять же - зачем? Какое применение?
-
ок, спасибо буду копать pulseaudio
Пользователь @Alex_Jet написал в Голосовое управление IH:
Но опять же - зачем? Какое применение?
так уже сложилось, как я писал выше, что уже существующие потолочные динамики хотя и находятся недалеко от OPIz физически я их подключить не могу не нарушив ремонта, поэтому буду запускать звук через LAN на ту железяку к которой подключены эти динамики
-
@div115, по мне - легче аккуратно демонтировать полотно потолка (есть успешный опыт), если это конечно натяжной потолок, а не гипсокартонный, чем плясать с бубном). Если гиспокартонная конструкция, то наверное лучше освоить pulse audio)
-
Пользователь @Alex_Jet написал в Голосовое управление IH:
@div115, по мне - легче аккуратно демонтировать полотно потолка (есть успешный опыт), если это конечно натяжной потолок, а не гипсокартонный, чем плясать с бубном). Если гиспокартонная конструкция, то наверное лучше освоить pulse audio)
потолок совмещенный - лдсп + натяжной, - на стыке вклеена светодиодная полоса в алюминиевом корпусе, поверх потолка поклеены ПВХ плинтуса, для того что-бы все исправить - надо пройти этот стык.
так что я попробую разобраться с pulseaudio, если все будет совсем коряво, - то буду химичить с доп usb колонками.
за участие и за советы - Большое спасибо!